



В этой статье мы рассмотрим настройку отказоустойчивой конфигурации из двух прокси серверов squid для доступа пользователей в Интернет из корпоративной сети с простой балансировкой нагрузки через Round Robin DNS. Для построения отказоустойчивой конфигурации мы создадим HA-кластер с помощью keepalived.
HA-кластер — это группа серверов с заложенной избыточностью, которая создается с целью минимизации времени простоя приложения, в случае аппаратных или программных проблем одного из членов группы. Исходя из этого определения, для работы HA-кластера необходимо реализовать следующее:
- Проверка состояния серверов;
- Автоматическое переключение ресурсов в случае отказа сервера;
Обе эти задачи позволяет выполнить keepalived. Keepalived – системный демон на Linux системах, позволяющего организовать отказоустойчивость сервиса и балансировку нагрузки. Отказоустойчивость достигается за счет “плавающего» IP адреса, который переключается на резервный сервер в случае отказа основного. Для автоматического переключения IP адреса между серверами keepalived используется протокол VRRP (Virtual Router Redundancy Protocol), он стандартизирован, описан в RFC (https://www.ietf.org/rfc/rfc2338.txt).
Принципы работы протокола VRRP
В первую очередь нужно рассмотреть теорию и основные определения протокола VRRP.
- VIP — Virtual IP, виртуальный IP адрес, который может автоматически переключаться между серверами в случае сбоев;
- Master — сервер, на котором в данный момент активен VIP;
- Backup — сервера на которые переключится VIP, в случае сбоя мастера;
- VRID — Virtual Router ID, сервера объединенные общим виртуальным IP(VIP) образуют так называемый виртуальный роутер, уникальный идентификатор которого, принимает значения от 1 до 255. Сервер может одновременно состоять в нескольких VRID, при этом для каждой VRID должны использоваться уникальные виртуальные IP адреса.
Общий алгоритм работы:
- Master сервер с заданным интервалом отправляет VRRP пакеты на зарезервированный адрес multicast (многоадресной) рассылки 224.0.0.18, а все slave сервера слушают этот адрес. Multicast рассылка — это когда отправитель один, а получателей может быть много.Важно. Для работы серверов в режиме multicast, сетевое оборудование должно поддерживать передачу multicast трафика.
- Если Slave сервер не получает пакеты, он начинает процедуру выбора Master и если он переходит в состояние Master по приоритету, то активирует VIP и отравляет gratuitous ARP. Gratuitous ARP — это особый вид ARP ответа, который обновляет MAC таблицу на подключенных коммутаторах, чтобы проинформировать о смене владельца виртуального IP адреса и mac адреса для перенаправления трафика.
Установка и настройка keepalived на CentOS
Установку и настройку будем проводить на примере серверов proxy-serv01 и proxy-serv02 на Centos 7 с установленным прокси сервером Squid. В нашей схеме мы будем использовать простейший способ распределения (балансировки) нагрузки — Round Robin DNS. Этот способ предполагает, что для одного имени в DNS регистрируется несколько IP адресов, и клиенты, при запросе получают поочередно сначала один адрес, потом другой. Поэтому нам понадобится два виртуальных IP адреса, которые будут зарегистрированы в DNS на одно имя и на которые в итоге будут обращаться клиенты. Схема сети:
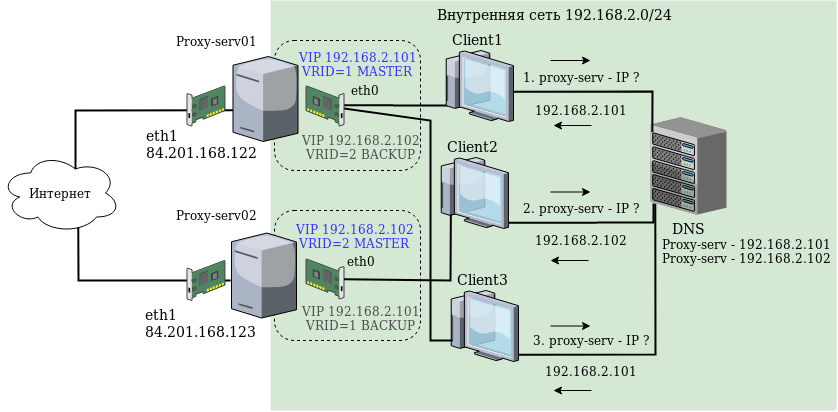
У каждого Linux сервера есть два физических сетевых интерфейса: eth1 с белым IP адресом и доступом в Интернет, и eth0 в локальной сети.
В качестве реальных IP адресов серверов используются:
192.168.2.251 — для proxy-server01
192.168.2.252 — для proxy-server02
В качестве виртуальных IP адресов, которые будут автоматически переключаться между серверами в случае сбоев используются:
192.168.2.101
192.168.2.102
Установить пакет keepalived нужно на обоих серверах, командой:
yum install keepalived
После завершения установки на обоих серверах правим конфигурационный файл
/etc/keepalived/keepalived.conf
Цветом выделены строки с отличающимися параметрами:
| на сервере proxy-serv01 | на сервере proxy-serv02 |
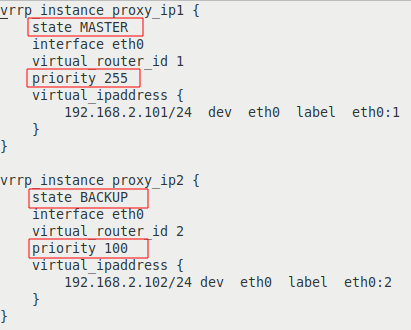 | 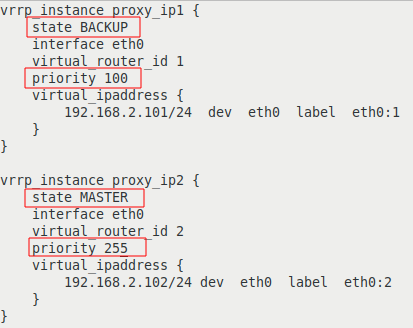 |
Разберем опции более подробно:
- vrrp_instance <название> — секция, определяющая экземпляр VRRP;
- state <MASTER|BACKUP> — начальное состояние при запуске;
- interface <название интефейса> — интерфейс, на котором будет работать VRRP;
- virtual_router_id <число от 0 до 255> — уникальный идентификатор VRRP экземпляра, должен совпадать на всех серверах;
- priority <число от 0 до 255> — задает приоритет при выборе MASTER, сервер с большим приоритетом становится MASTER;
- virtual_ipaddress — блок виртуальных IP адресов, которые будут активны на сервере в состоянии MASTER. Должны совпадать на всех серверах внутри VRRP экземпляра.
Если текущая сетевая конфигурация не позволяет использовать multicast, в keepalived есть возможность использовать unicast, т.е. передавать VRRP пакеты напрямую серверам, которые задаются списком. Чтобы использовать unicast, понадобятся опции:
- unicast_src_ip — адрес источник для VRRP пакетов;
- unicast_peer — блок IP адресов серверов, на которые будут рассылаться VRPP пакеты.
Таким образом, наша конфигурация определяет два VRRP экземпляра, proxy_ip1 и proxy_ip2. При штатной работе, сервер proxy-serv01 будет MASTER для виртуального IP 192.168.2.101 и BACKUP для 192.168.2.102, а сервер proxy-serv02 наоборот, будет MASTER для виртуального IP 192.168.2.102, и BACKUP для 192.168.2.101.
Если на сервере активирован файрвол, то нужно добавить разрешающие правила для multicast траффика и vrrp протокола с помощью iptables:
iptables -A INPUT -i eth0 -d 224.0.0.0/8 -j ACCEPT
iptables -A INPUT -p vrrp -i eth0 -j ACCEPT
Активируем автозагрузки и запустим службу keepalived на обоих серверах:
systemctl enable keepalived
systemctl start keepalived
После запуска службы keepalived, виртуальные IP будут присвоены интерфейсам из конфигурационного файла. Посмотрим текущие IP адреса на интерфейсе eth0 серверов:
ip a show eth0
На сервере proxy-serv01:

На сервере proxy-serv02:

Keepalived: отслеживание состояния приложений и интерфейсов
Благодаря протоколу VRRP штатно обеспечивается мониторинг состояния сервера, например, при полном физическом отказе сервера, или сетевого порта на сервере или коммутаторе. Однако, возможны и другие проблемные ситуации:
- ошибка в работе службы прокси сервера — клиенты, которые попадут на виртуальный адрес этого сервера, будут получать сообщение в браузере с ошибкой, что прокси сервер недоступен;
- отказ в работе второго интерфейса в интернет — клиенты, которые попадут на виртуальный адрес этого сервера, будут получать сообщение в браузере с ошибкой, что не удалось установить соединение.
Для обработки перечисленных выше ситуаций, воспользуемся следующими опциями:
- track_interface — мониторинг состояния интерфейсов, переводит VRRP экземпляр в состояние FAULT, если один из перечисленных интерфейсов находится в состоянии DOWN;
- track_script — мониторинг с использованием скрипта, который должен возвращать 0 если проверка завершилась успешно , 1 — если проверка завершилась с ошибкой.
Обновим конфигурацию, добавим мониторинг интерфейса eth1 (по умолчанию, VRRP экземпляр будет проверять интерфейс, к которому он привязан, т.е. в текущей конфигурации eth0):
track_interface {
eth1
}
Директива track_script запускает скрипт с параметрами, определенными в блоке vrrp_script, который имеет следующий формат:
vrrp_script <название> {
script <"путь к исполняемому файлу">
interval <число, секунд> - периодичность запуска скрипта, по умолчанию 1 секунда
fall <число> - количество раз, которое скрипт вернул не нулевое значение, при котором перейти в состояние FAULT
rise <число> - количество раз, которое скрипт вернул нулевое значение, при котором выйти из состояния FAULT
timeout <число> - время ожидания, пока скрипт вернет результат, после которого вернуть ненулевое значение.
weight <число> - значение, на которое будет уменьшен приоритет сервера, в случае перехода в состояние FAULT. По умолчанию 0, что означает, что сервер перейдет в состояние FAULT, после неудачного выполнения скрипта за количество раз, определенное параметром fall.
}
Настроим мониторинг работы Squid. Проверить, что процесс активен, можно командой:
squid -k check
Создадим vrrp_script, с параметрами периодичности выполнения каждые 3 секунды. Этот блок определяется за пределами блоков vrrp_instance.
vrrp_script chk_squid_service {
script "/usr/sbin/squid -k check"
interval 3
}
Добавим наш скрипт в мониторинг, внутри обоих блоков vrrp_instance:
track_script {
chk_squid_service
}
Теперь при ошибке в работе службы прокси Squid, виртуальный IP адрес переключится на другой сервер.
Вы можете добавить дополнительные действия при изменении состояния сервера.
Если Squid настроен на прием подключений с любого интерфейса, т.е. http_port 0.0.0.0:3128, то при переключении виртуального IP адреса, никаких проблем не возникнет, Squid будет принимать подключения на новом адресе. Но, если настроены конкретные IP адреса, например:
http_port 192.168.2.101:3128 http_port 192.168.2.102:3128
то Squid не узнает о том, что в системе появился новый адрес, на котором нужно слушать запросы от клиентов. Для обработки подобных ситуаций, когда нужно выполнить дополнительные действия при переключении виртуального IP адреса, в keepalived заложена возможность выполнения скрипта при наступлении события изменения состояния сервера, например, с MASTER на BACKUP, или наоборот. Реализуется опцией:
notify "путь к исполняемому файлу"
Keepalived: тестирование переключения при отказе
После настройки виртуальных IP, проверим, насколько корректно происходит обработка сбоев. Первая проверка — имитация сбоя одного из серверов. Отключим от сети внутренний сетевой интерфейс eth0 сервера proxy-serv01, при этом он перестанет отправлять VRRP пакеты и сервер proxy-serv02 должен активировать у себя виртуальный IP адрес 192.168.2.101. Результат проверим командой:
ip a show eth0
На сервере proxy-serv01:
![]()
На сервере proxy-serv02:
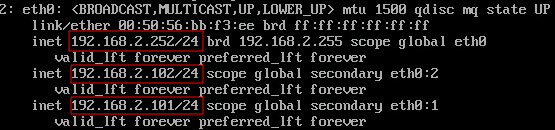
Как и ожидалось, сервер proxy-serv02 активировал у себя виртуальный IP адрес 192.168.2.101. Посмотрим, что при этом происходило в логах, командой:
cat /var/log/messages | grep -i keepalived
| на сервере proxy-serv01 | на сервере proxy-serv02 |
Keepalived_vrrp[xxxxx]: Kernel is reporting: interface eth0 DOWN Keepalived_vrrp[xxxxx]: VRRP_Instance(proxy_ip1) Entering FAULT STATE Keepalived_vrrp[xxxxx]: VRRP_Instance(proxy_ip1) removing protocol VIPs. Keepalived_vrrp[xxxxx]: VRRP_Instance(proxy_ip1) Now in FAULT state |
Keepalived_vrrp[xxxxx]: VRRP_Instance(proxy_ip1) Transition to MASTER STATE |
| Keepalived получает сигнал, что интерфейс eth0 находится в состоянии DOWN, и переводит VRRP экземпляр proxy_ip1 в состояние FAULT, освобождая виртуальные IP адреса. | Keepalived переводит VRRP экземпляр proxy_ip1 в состояние MASTER, активирует адрес 192.168.2.101 на интерфейсе eth0 и отправляет gratuitous ARP. |


И проверим, что после включения в сеть интерфейса eth0 на сервере proxy-serv01, виртуальный IP 192.168.2.101 переключится обратно.
| на сервере proxy-serv01 | на сервере proxy-serv02 |
Keepalived_vrrp[xxxxx]: VRRP_Instance(proxy_ip1) forcing a new MASTER election Keepalived_vrrp[xxxxx]: VRRP_Instance(proxy_ip1) Transition to MASTER STATE Keepalived_vrrp[xxxxx]: VRRP_Instance(proxy_ip1) Entering MASTER STATE Keepalived_vrrp[xxxxx]: VRRP_Instance(proxy_ip1) setting protocol VIPs. Keepalived_vrrp[xxxxx]: Sending gratuitous ARP on eth0 for 192.168.2.101 |
Keepalived_vrrp[xxxxx]: VRRP_Instance(proxy_ip1) Received advert with higher priority 255, ours 100 Keepalived_vrrp[xxxxx]: VRRP_Instance(proxy_ip1) Entering BACKUP STATE Keepalived_vrrp[xxxxx]: VRRP_Instance(proxy_ip1) removing protocol VIPs. |
| Keepalived получает сигнал о восстановлении интерфейса eth0 и начинает новые выборы MASTER для VRRP экземпляра proxy_ip1. После перехода в состояние MASTER, активирует адрес 192.168.2.101 на интерфейсе eth0 и отправляет gratuitous ARP. | Keepalived получает пакет с большим приоритетом для VRRP экземпляра proxy_ip1 и переводит proxy_ip1 в состояние BACKUP и освобождает виртуальные IP адреса. |
Вторая проверка – имитация сбоя интерфейса внешний сети, для этого отключим от сети внешний сетевой интерфейс eth1 сервера proxy-serv01. Результат проверки проконтролируем по логам.
| на сервере proxy-serv01 | на сервере proxy-serv02 |
Keepalived_vrrp[xxxxx]: Kernel is reporting: interface eth1 DOWN Keepalived_vrrp[xxxxx]: VRRP_Instance(proxy_ip1) Entering FAULT STATE Keepalived_vrrp[xxxxx]: VRRP_Instance(proxy_ip1) removing protocol VIPs. Keepalived_vrrp[xxxxx]: VRRP_Instance(proxy_ip1) Now in FAULT state |
Keepalived_vrrp[xxxxx]: VRRP_Instance(proxy_ip1) Transition to MASTER STATE Keepalived_vrrp[xxxxx]: VRRP_Instance(proxy_ip1) Entering MASTER STATE Keepalived_vrrp[xxxxx]: VRRP_Instance(proxy_ip1) setting protocol VIPs. Keepalived_vrrp[xxxxx]: Sending gratuitous ARP on eth0 for 192.168.2.101 |
| Keepalived получает сигнал, что интерфейс eth1 находится в состоянии DOWN, и переводит VRRP экземпляр proxy_ip1 в состояние FAULT, освобождая виртуальные IP адреса. | Keepalived переводит VRRP экземпляр proxy_ip1 в состояние MASTER, активирует адрес 192.168.2.101 на интерфейсе eth0 и отправляет gratuitous ARP. |

Третья проверка — имитация сбоя работы службы прокси Squid, для этого вручную оставим службу командой:
systemctl stop squid
Результат проверки проконтролируем по логам.
| на сервере proxy-serv01 | на сервере proxy-serv02 |
Keepalived_vrrp[xxxxx]: VRRP_Script(chk_squid_service) failed Keepalived_vrrp[xxxxx]: VRRP_Instance(proxy_ip1) Entering FAULT STATE Keepalived_vrrp[xxxxx]: VRRP_Instance(proxy_ip1) removing protocol VIPs. Keepalived_vrrp[xxxxx]: VRRP_Instance(proxy_ip1) Now in FAULT state |
Keepalived_vrrp[xxxxx]: VRRP_Instance(proxy_ip1) Transition to MASTER STATE Keepalived_vrrp[xxxxx]: VRRP_Instance(proxy_ip1) Entering MASTER STATE Keepalived_vrrp[xxxxx]: VRRP_Instance(proxy_ip1) setting protocol VIPs. Keepalived_vrrp[xxxxx]: Sending gratuitous ARP on eth0 for 192.168.2.101 |
| Скрипт проверки активности службы прокси squid завершается с ошибкой. Keepalived переводит VRRP экземпляр proxy_ip1 в состояние FAULT, освобождая виртуальные IP адреса. | Keepalived переводит VRRP экземпляр proxy_ip1 в состояние MASTER, активирует адрес 192.168.2.101 на интерфейсе eth0 и отправляет gratuitous ARP. |
Все три проверки пройдены успешно, keepalived настроен корректно. В продолжении этой статьи будет произведена настройка HA-кластера с помощью Pacemaker, и рассмотрена специфика каждого из этих инструментов.
Итоговый конфигурационный файл /etc/keepalived/keepalived.conf для сервера proxy-serv01:
vrrp_script chk_squid_service {
script "/usr/sbin/squid -k check"
interval 3
}
vrrp_instance proxy_ip1 {
state MASTER
interface eth0
virtual_router_id 1
priority 255
virtual_ipaddress {
192.168.2.101/24 dev eth0 label eth0:1
}
track_interface {
eth1
}
track_script {
chk_squid_service
}
}
vrrp_instance proxy_ip2 {
state BACKUP
interface eth0
virtual_router_id 2
priority 100
virtual_ipaddress {
192.168.2.102/24 dev eth0 label eth0:2
}
track_interface {
eth1
}
track_script {
chk_squid_service
}
}
Итоговый конфигурационный файл /etc/keepalived/keepalived.conf для сервера proxy-serv02:
vrrp_script chk_squid_service {
script "/usr/sbin/squid -k check"
interval 3
}
vrrp_instance proxy_ip1 {
state BACKUP
interface eth0
virtual_router_id 1
priority 100
virtual_ipaddress {
192.168.2.101/24 dev eth0 label eth0:1
}
track_interface {
eth1
}
track_script {
chk_squid_service
}
}
vrrp_instance proxy_ip2 {
state MASTER
interface eth0
virtual_router_id 2
priority 255
virtual_ipaddress {
192.168.2.102/24 dev eth0 label eth0:2
}
track_interface {
eth1
}
track_script {
chk_squid_service
}
}


Хорошая статья, спасибо. А можно сделать, чтобы был один виртуальный ip и у клиентов он стоял шлюзом по умолчанию, а при сборе происходило переключение на резервный сервер. И ещё вопрос, как вы клиентам раздаете сразу 2 прокси или у вас в DNS, прописано одно имя, а настройки клиенты получают в браузере по имени сервера.
В принципе вы можете использовать плавающий IP и без привязки к какому-то сервису, но что обеспечивает этот ip?
Клиенты подключатся по DNS имени. DNS отдает один из IP адресов (тем самым мы делим/ балансируем нагрузку на сервера пополам). В аварийном режиме оба IP живут на одном хосте, клиенты при это ничего не замечают (но возможна просадка производительности)
Плавающий IP например может обеспечивать, шлюз по умолчанию, если мы будем использовать на ПК, только один адрес сервера, чтобы не прописывать несколько адресов, такое возможно реализовать?
В принципе да, так можно обеспечить отказоустойчивый дефолтный gateway для клиентов. Но вам придется держать 2 сервера — марштутизатора. Обычно эту роль выполняют все-таки сетевые железки. Но если вам критично именно отказоустойчивость шлюза — keepalived думаю подойдет.
Здравствуйте можно настроить keepalived если ip будут внешними и при этом разными не из одной подсети?
Прошел год. Было ли оно, это продолжение? Или оно так и осталось только в планах? Или я его не нашёл?