



В этой статье мы рассмотрим пошаговую установку и настройку групп доступности Always On в SQL Server в Windows Server 2019, рассмотрим сценарии отработки отказов и ряд других смежных вопросов.
“Always On Availability Groups” или “Группы доступности Always On” это технология для обеспечения высокой доступности в SQL Server. Always On появились в релизе Microsoft SQL Server 2012.
Особенности групп доступности Always On в SQL Server
Для чего могут использоваться группы доступности SQL Server?
- Высокая доступность MS SQL и автоматическая отработка отказа;
- Балансировка нагрузки select запросов между узлами (вторичные реплики могут быть доступны для чтения);
- Резервное копирование с вторичных реплик;
- Избыточность данных. Каждая реплика хранит копии баз данных группы доступности.
Always On работает на платформе Windows Server Failover Cluster (WSFC). WSFC обеспечивает мониторинг узлов участвующих в группе доступности и может осуществлять автоматическую отработку отказа посредством голосования между узлами. Начиная с MS SQL Server 2017 появилась возможность использовать Always On без WSFC, в том числе на Linux системах. При построении кластера на Linux можно использовать Pacemaker как альтернативу WSFC.
Always On доступен в Standard редакции, но с некоторыми ограничениями:
- Лимит на 2 реплики (основную и вторичную);
- Вторичная реплика не может быть использована для read доступа;
- Вторичная реплика не может быть использована для резервного копирования MS SQL;
- Поддержка только 1 базы данных на группу доступности.
В редакции Enterprise ограничений нет.
Разберемся в терминологии:
- Группу доступности Always ON – это набор реплик и баз данных;
- Реплика – это экземпляр SQL Server находящийся в группе доступности. Реплика может быть основная (primary) и вторичная (secondary). Каждая реплика может содержать одну или более баз данных.
В основе Always On лежит WSFC. Каждый узел группы доступности должен быть членом отказоустойчивого кластера Windows. Каждый экземпляр SQL Server может иметь несколько групп доступности. В каждой группе доступности может быть до 8 вторичных реплик.
При отказе основой реплики, кластер проголосует за новую основную реплику и Always On переведёт одну из вторичных реплик в статус основной. Так как при работе с Always On пользователи соединяются с прослушивателем кластера (или Listener, то есть специальный IP адрес кластера и соответствующее ему DNS имя), то возможность выполнять write запросы полностью восстановится. Прослушиватель также отвечает за балансировку select запросов между вторичными репликами.
Настройка Windows Server Failover Cluster для Always On
Прежде всего нам нужно настроить отказоустойчивый кластер на всех узлах, которые будут участвовать в Always On.
Моя конфигурация:
- 2 виртуальных машины на Hyper-V с Windows Server 2019;
- 2 экземпляра SQL Server 2019 редакции Enterprise;
- Hostname узлов – testnode1 и testnode2. Имя экземпляров node1 и node2.
В Server Manager добавляем роль Failover Clustering, или установите компонент с помощью PowerShell:
Install-WindowsFeature –Name Failover-Clustering –IncludeManagementTools
Установка автоматическая, ничего настраивать пока не нужно. После окончания установки запустите оснастку Failover Cluster Manager (FailoverClusters.SnapInHelper.msc).
Создаём новый кластер.
Добавляем имена серверов, которые будут участвовать в кластере.
Дальше мастер предлагает пройти тесты. Не отказываемся, выбираем первый пункт.
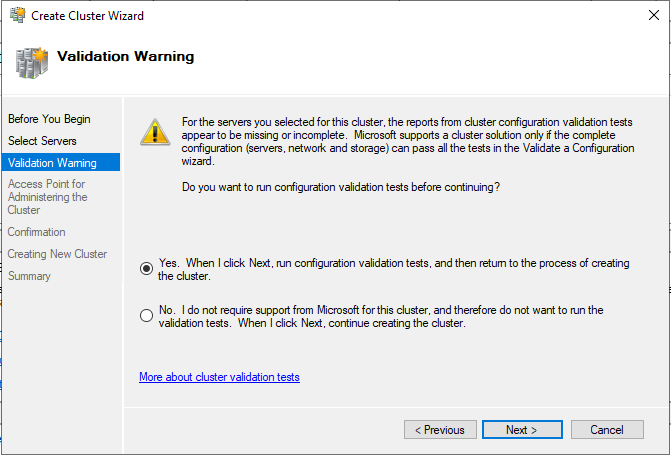
Указываем имя кластера, выбираем сеть и IP адрес кластера. Имя кластера автоматически появится в DNS, прописывать его специально не нужно. В моём случае имя кластера – ClusterAG.
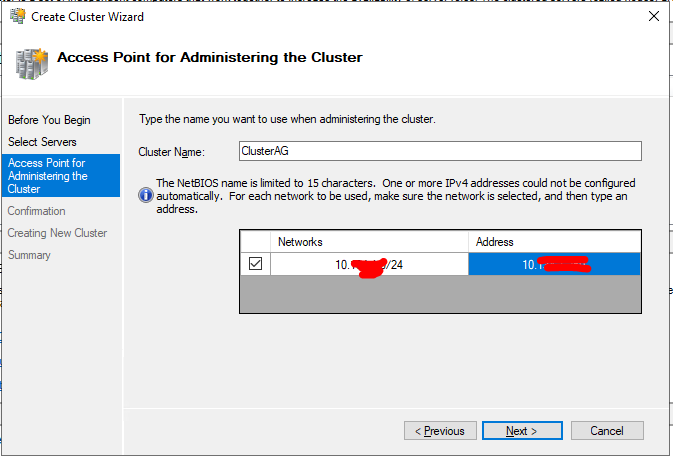
Убираем чебокс “Add all eligible storage to the cluster”, так как диски мы сможем добавить позже.
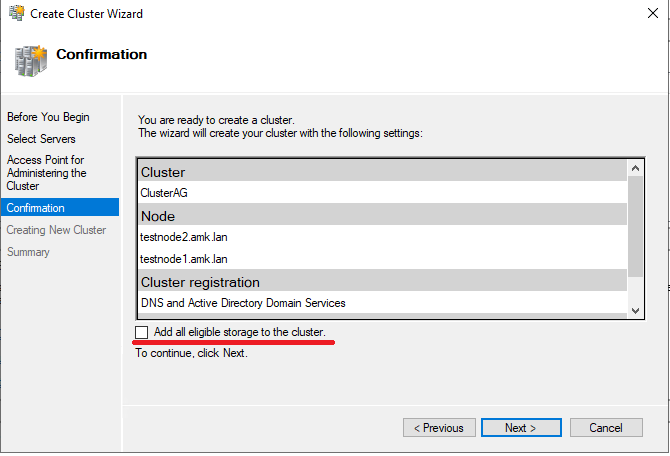
Узлов в кластере всего 2, поэтому необходимо настроить Cluster Quorum. Кворум кластера — это “решающий голос”. Например, если один из узлов кластера становится недоступен, кластеру необходимо определить какие узлы на самом деле доступны и могут видеть друг друга. Кворум нужен для согласованности кластера (Cluster -> More Actions -> Configure Cluster Quorum Settings).
Выберите тип кворума со свидетелем (quorum witness).
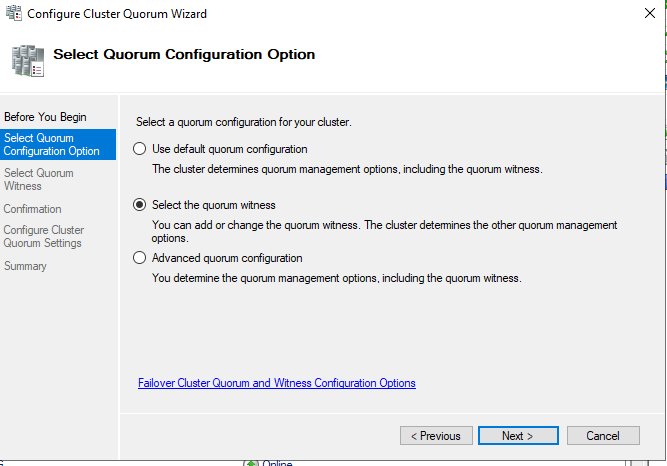
Затем выбираем тип свидетеля – сетевая папка (file share witness).
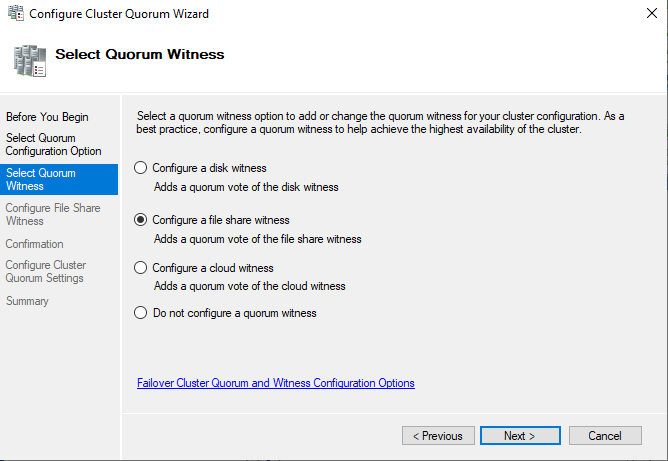
Укажите UNC путь к сетевой папке. Эту директорию нужно создать самостоятельно, и она обязательно должна быть на сервере, который не участвует в кластере.
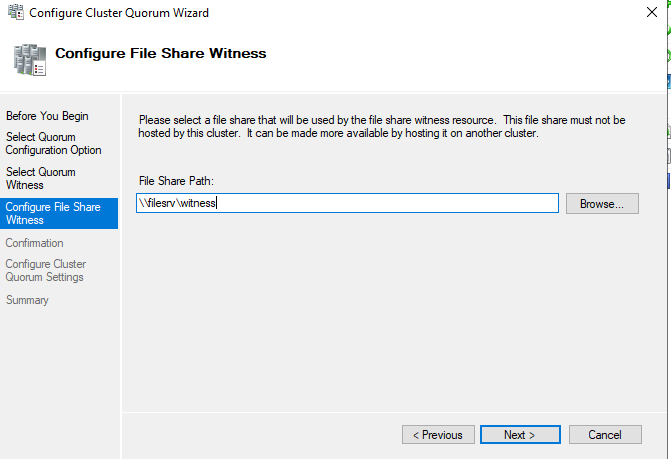
При настройке кластера вы можете получить ошибку:
There was an error configuring the file share witness. Unable to save property changes for File Share Witness. The system cannot find the file specified.
Скорее всего это значит, что у пользователя из-под которого работает кластер нет прав на эту сетевую папку. По-умолчанию кластер работает из-под локального пользователя. Вы можете дать права на эту папку всем компьютерам кластера, либо сменить аккаунт для службы кластера и раздать права ему.
На этом базовая конфигурация кластера закончена. Убедимся, что DNS кластера прописан и отдаёт правильный IP
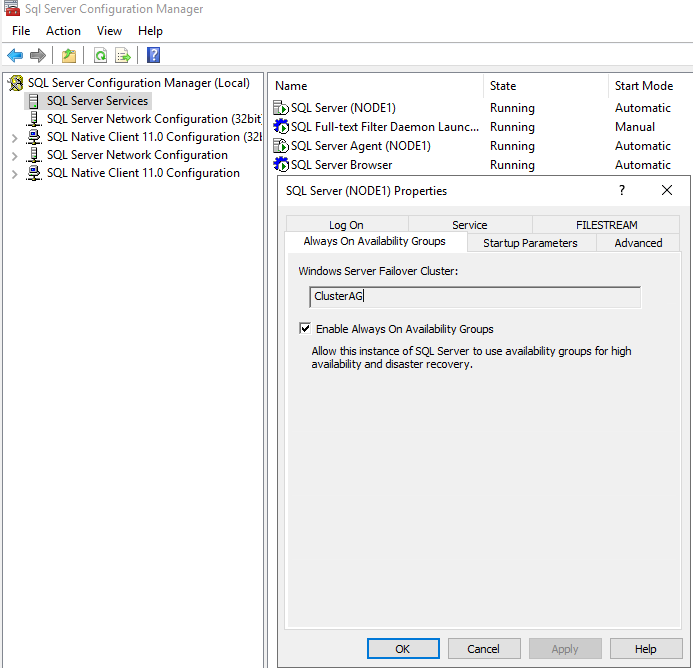
Настройка Always On в MS SQL Server
После стандартной установки экземпляра SQL Server вы можете включить и настроить группы доступности Always On. Их нужно включить в SQL Server Configuration Manager в свойствах экземпляра. Как видно на скриншоте, SQL Server уже определил, что он является участником кластера WSFC. Поставьте чекбокс “Enable Always On Availability Groups” и перезагрузите службу экземпляра MSSQL. Выполните те же действия на втором экземпляре.
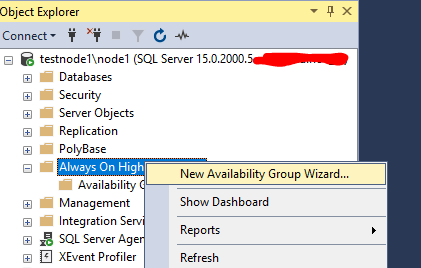
В SQL Server Management Studio щелкните по узлу “Always On High Availability” и запустите мастер настройки группы доступности (New Availability Group Wizard).
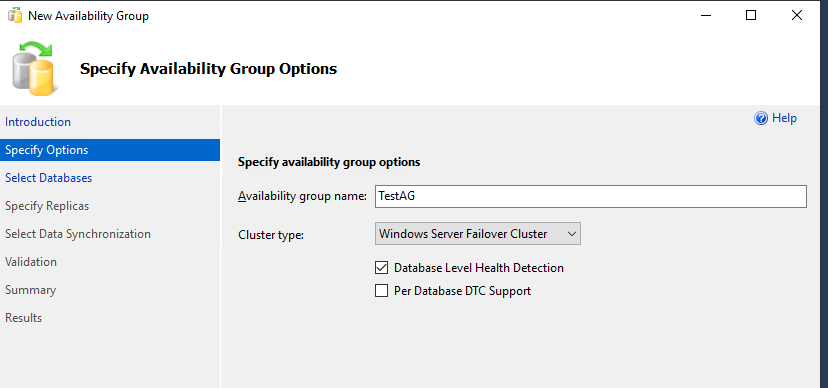
Укажите имя группы доступности Always On и выберите опцию “Database Level Health Detection”. С этой опцией Always On сможет определять, когда база данных находится в нездоровом состоянии.
Выберите базы данных SQL Server, которые будут участвовать в группе доступности Always On.
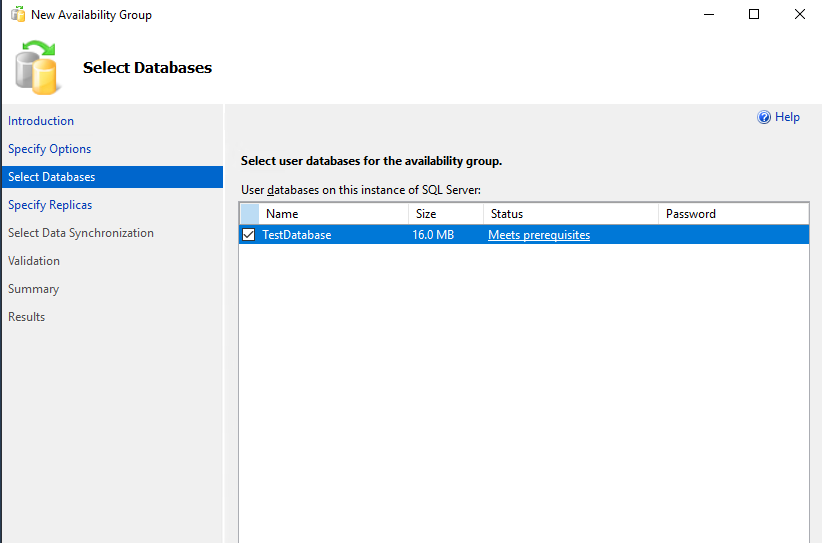
Нажмите “Add Replica…” и подключитесь к второму серверу SQL. Таким образом можно добавить до 8 серверов.
- Initial Role – роль реплики на момент создания группы. Может быть Primary и Secondary;
- Automatic Failover – если база данных станет недоступна, Always On переведёт primary роль на другую реплику. Отмечаем чекбокс;
- Availability Mode – возможно выбрать Synchronous Commit или Asynchronous Commit. При выборе синхронного режима, транзакции, поступающие на primary реплику, будут отправлены на все остальные вторичные реплики с синхронным режимом. Primary реплика завершит транзакцию только после того, как реплики запишут транзакцию на диск. Таким образом исключается возможность потери данных при сбое primary реплики. При асинхронном режиме основная реплика сразу записывает изменения, не дожидаясь ответа от вторичных реплик;
- Readable Secondary – параметр задающий возможность делать select запросы к вторичным репликам. При значении yes, клиенты даже при соединении без ApplicationIntent=readonly смогут получить read-only доступ;
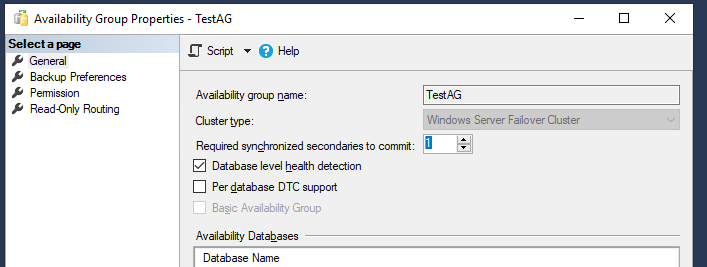
- Required synchronized secondaries to commit – число синхронизированных вторичных реплик для завершения транзакции. Нужно выставлять в зависимости от количества реплик, я поставлю 1. Имейте в виду, что, если вторичных синхронизированных реплик станет меньше указанного числа (например, при аварии), базы данных группы доступности станут недоступны даже для чтения.
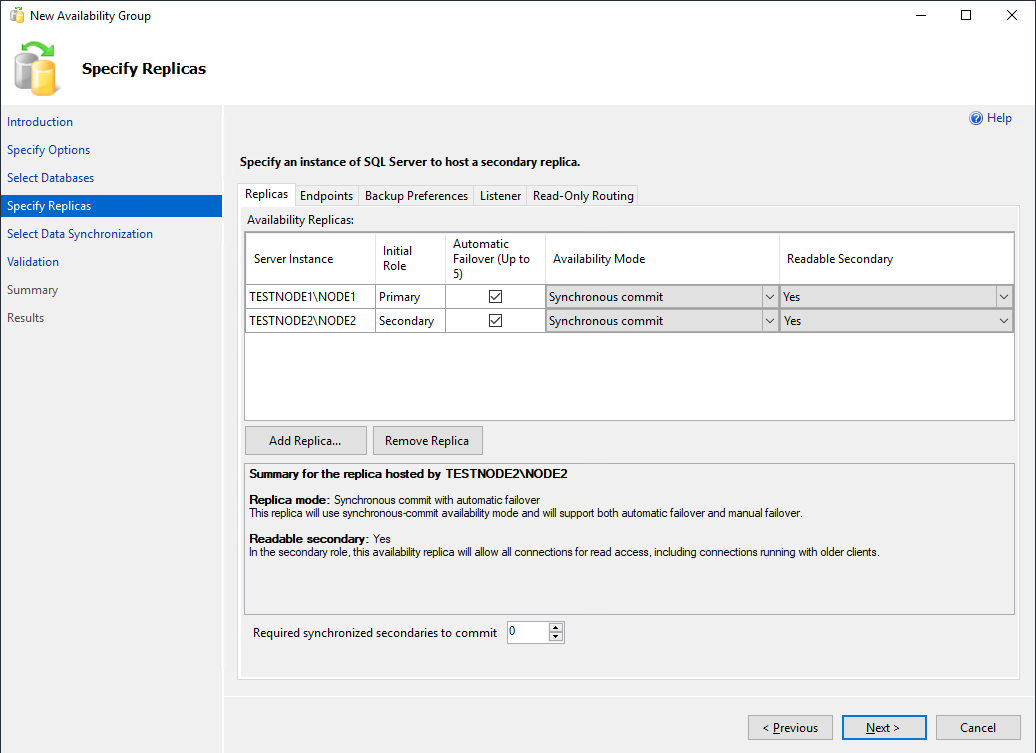
Вкладку Endpoints не трогаем.
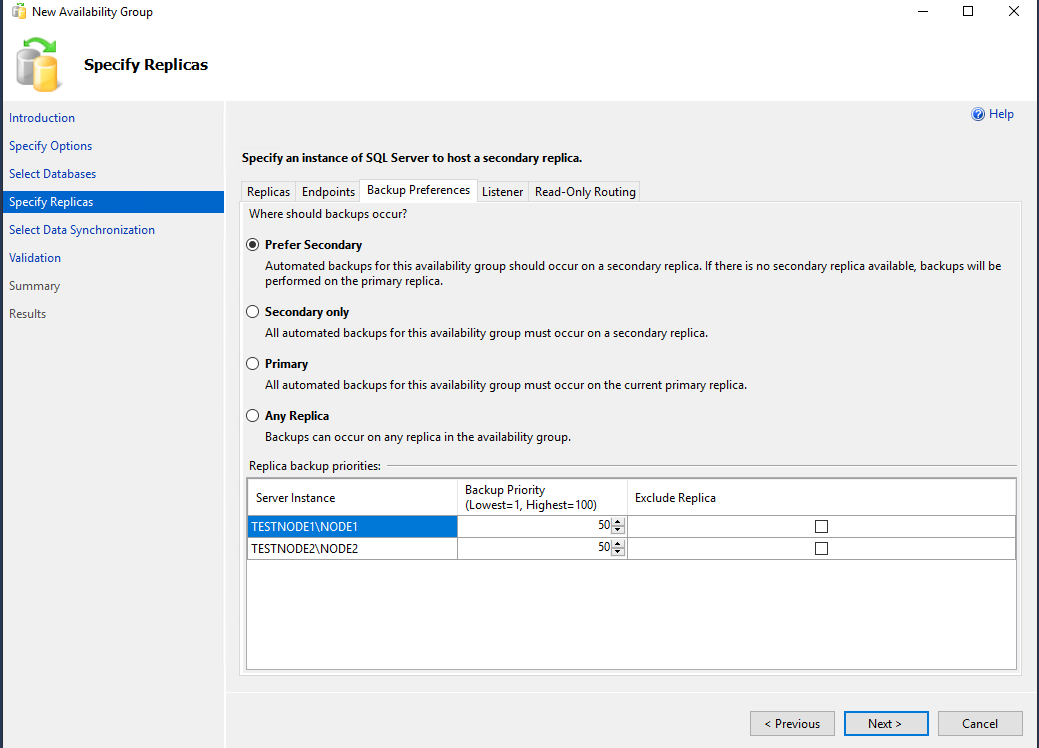
На вкладке Backup Preferences можно выбрать откуда будут делаться бекапы. Оставляем всё по умолчанию – Prefer Secondary.
Указываем имя слушателя группы доступности (availability group listener), порт и IP адрес.
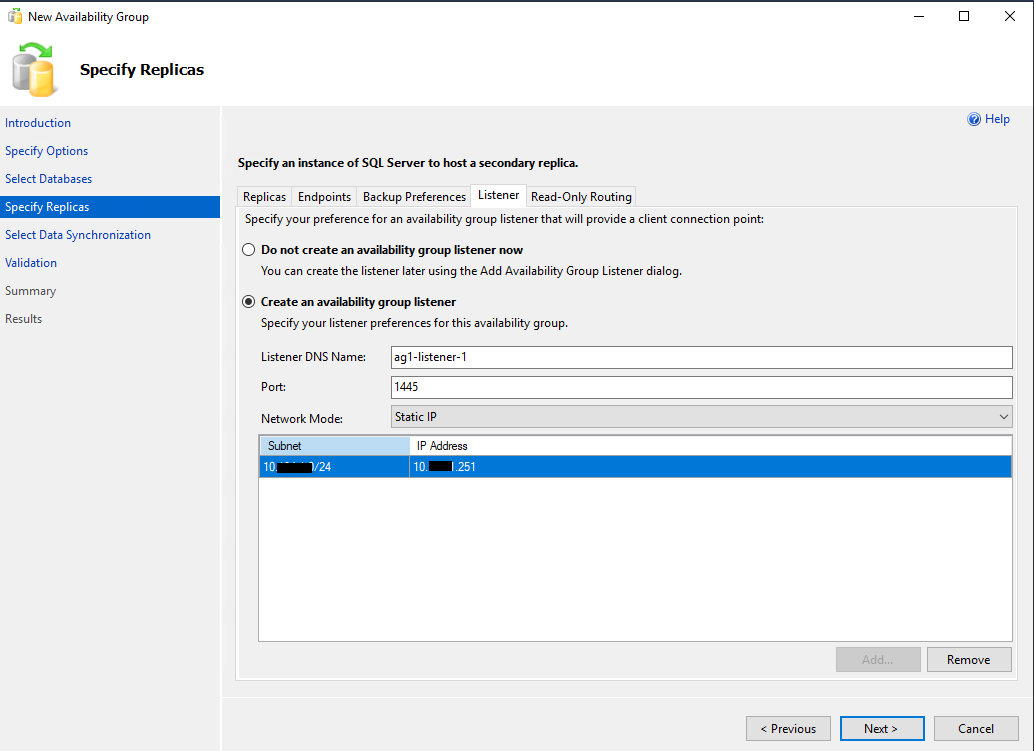
Вкладку Read-Only Routing оставляем без изменений.
Выбираем каким образом будут синхронизироваться реплики. Я оставляю первый пункт – автоматическую синхронизацию (Automatic seeding).
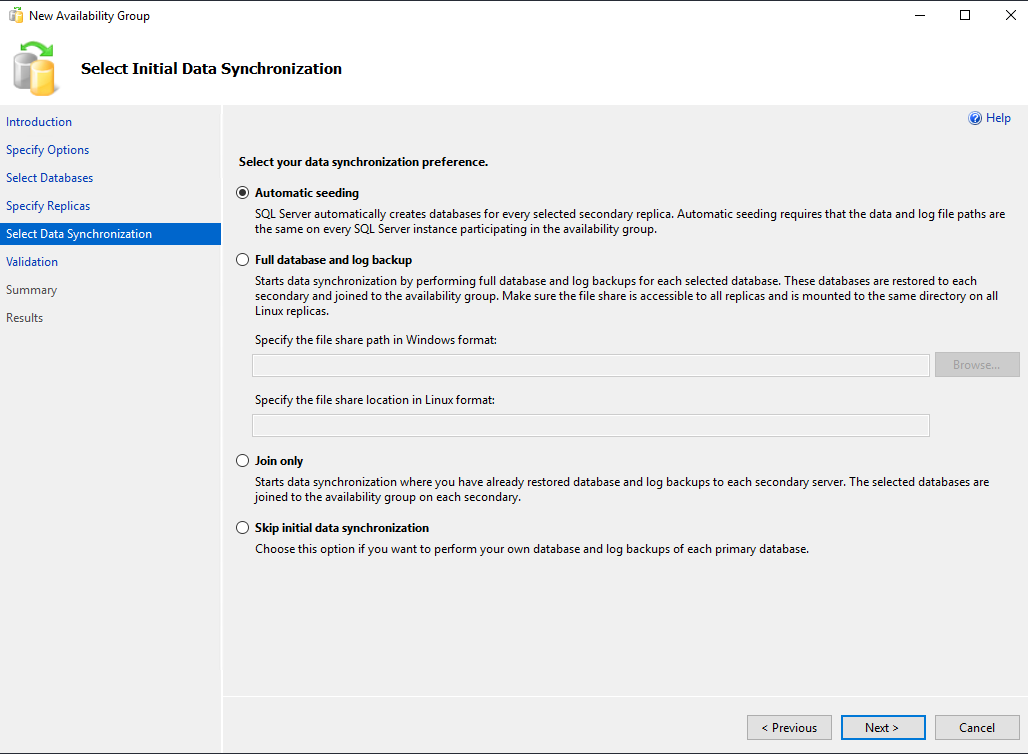
После этого ваши настройки должны пройти валидацию. Если ошибок нет, нажмите Finish для применения изменений.
В моём случае все тесты прошли успешно, но после установки на шаге Results, мастер сообщил об ошибке при создании слушателя группы доступности. В логах кластера была такая ошибка:
Cluster network name resource failed to create its associated computer object in domain.
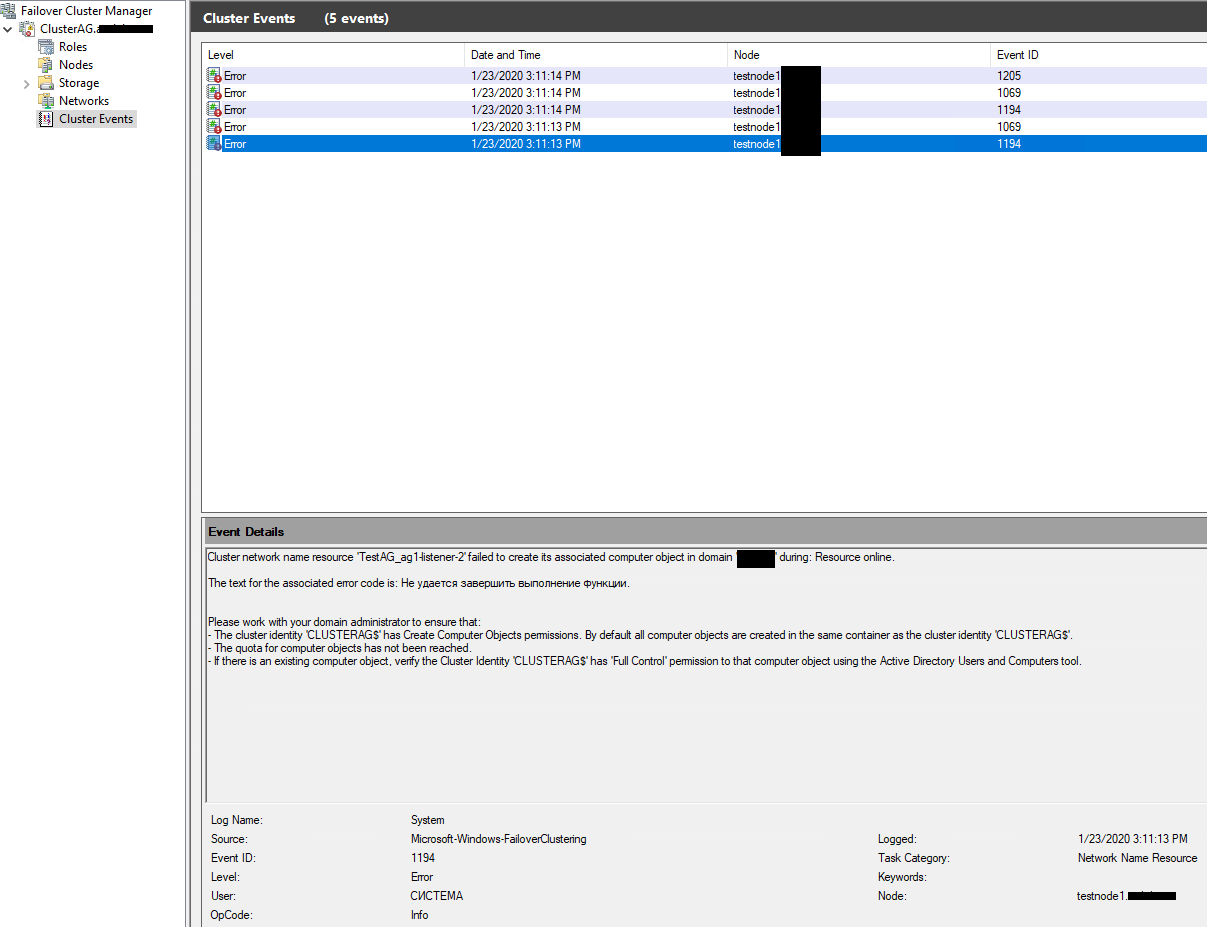
Это означает, что у кластера недостаточно прав для создания слушателя. В документации написано, что достаточно дать разрешение на создание объектов типа “компьютер” объекту вашего кластера. Проще всего это сделать через делегирование полномочий в AD (или, быстрый но плохой вариант — временно добавить объект CLUSTERAG$ в группу Domain Admins).
Так как группа доступности у меня создалась, а слушатель нет, я добавил его вручную. Вызываем контекстное меню на группе доступности и жмем Add Listener…
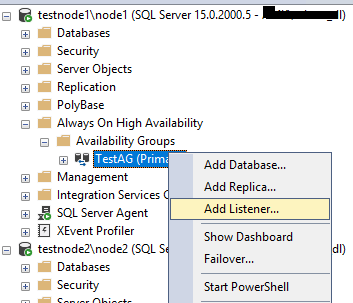
Укажите IP адрес, порт и DNS имя слушателя.
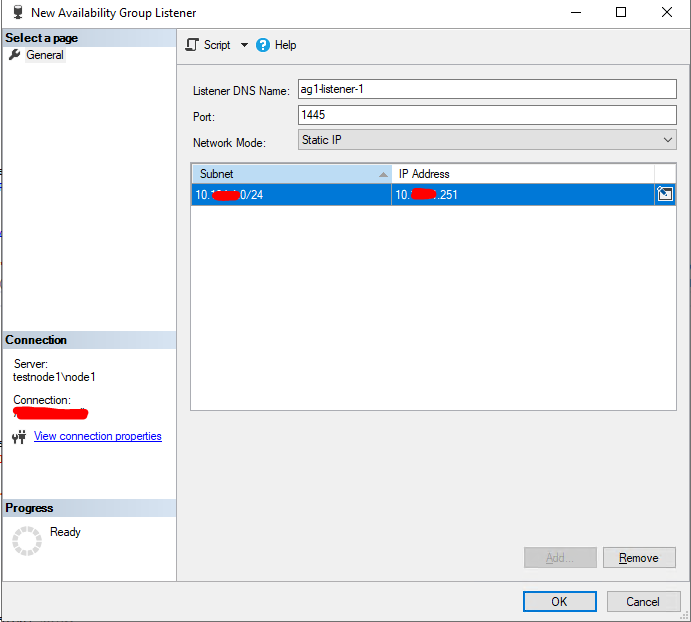
Проверьте, что Listener появился во разделе доступных слушателей группы Always On.
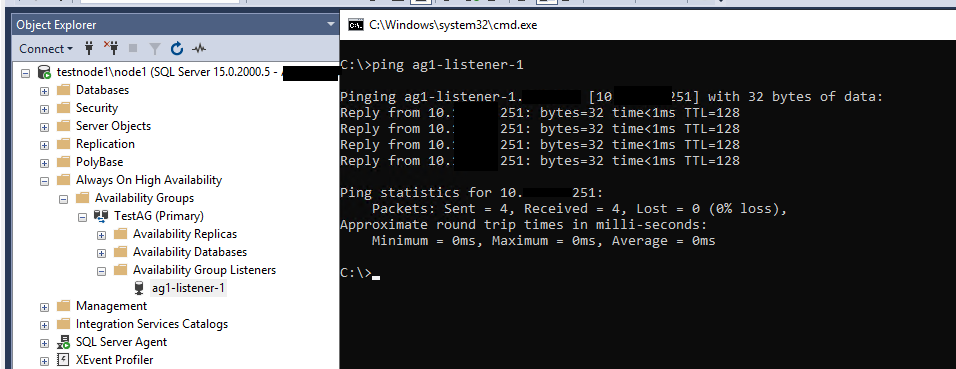
На этом базовая настройка группы доступности Always On закончена.
Always On: проверка работы, автоматическая отработка отказа
Посмотрим на панель мониторинга групп доступности (Show Dashboard).
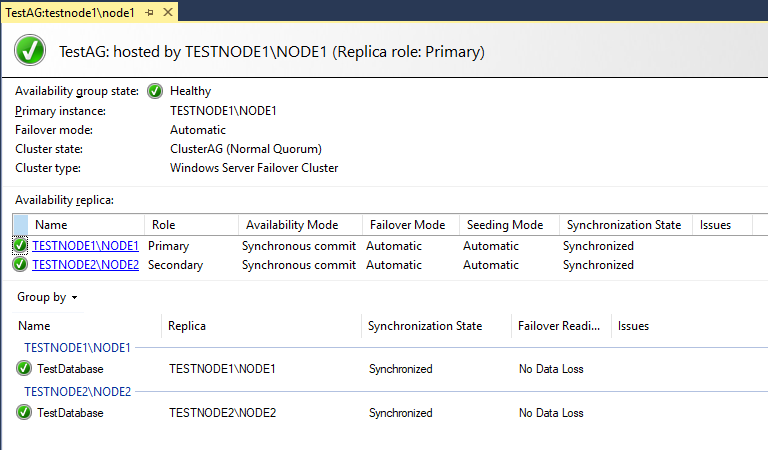
Все OK, группа доступности создана и работает.
Попробуем перевести основную роль на экземпляр node2 в ручном режиме. Щелкните ПКМ по группе доступности и выберите Failover.
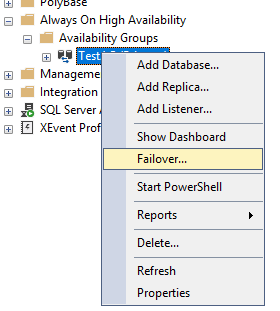
Стоит обратить внимание на пункт Failover Readiness. Значение No data loss значит, что потеря данных при переходе исключена.
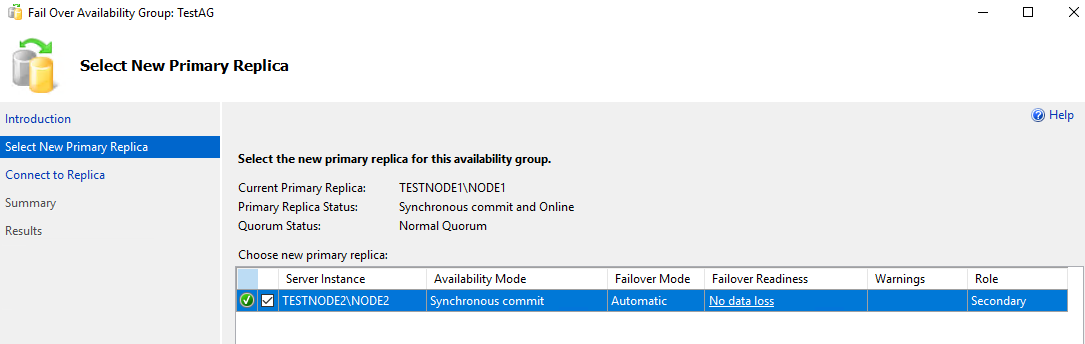
Соединяемся с node2.
Жмём Finish.
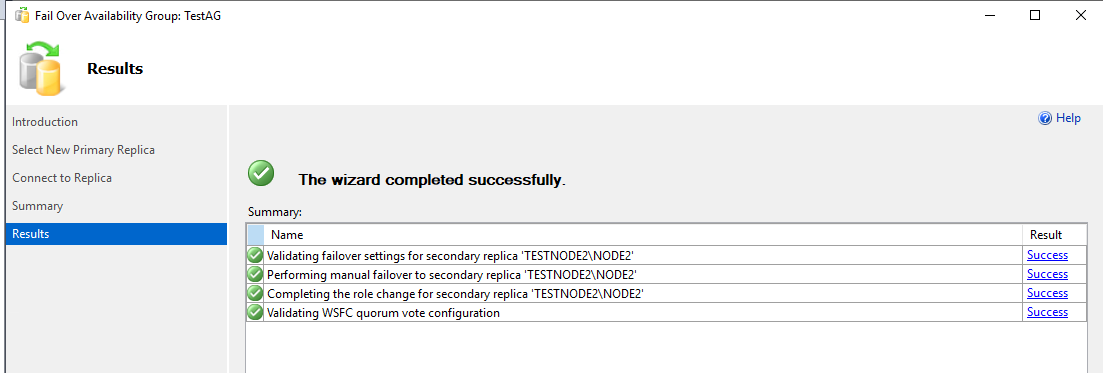
Проверяем, что node2 стал основной репликой в группе доступности (Primary Instance).
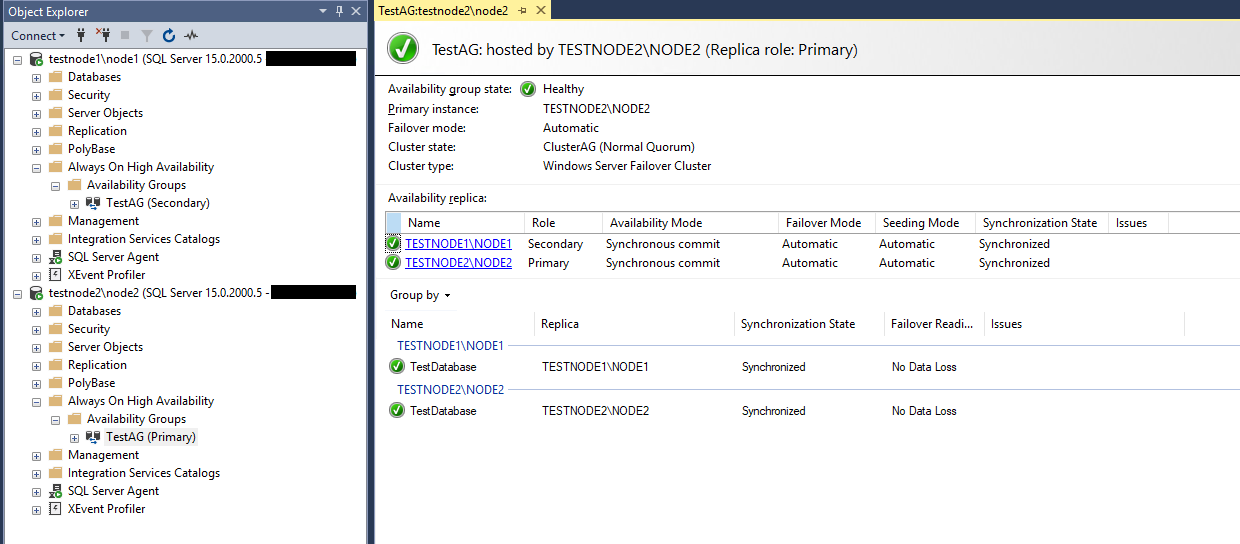
Убедимся, что слушатель работает как надо. В SSMS укажите DNS имя слушателе и порт через запятую:
ag1-listener-1,1445
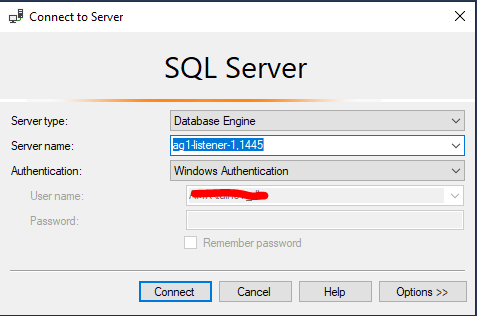
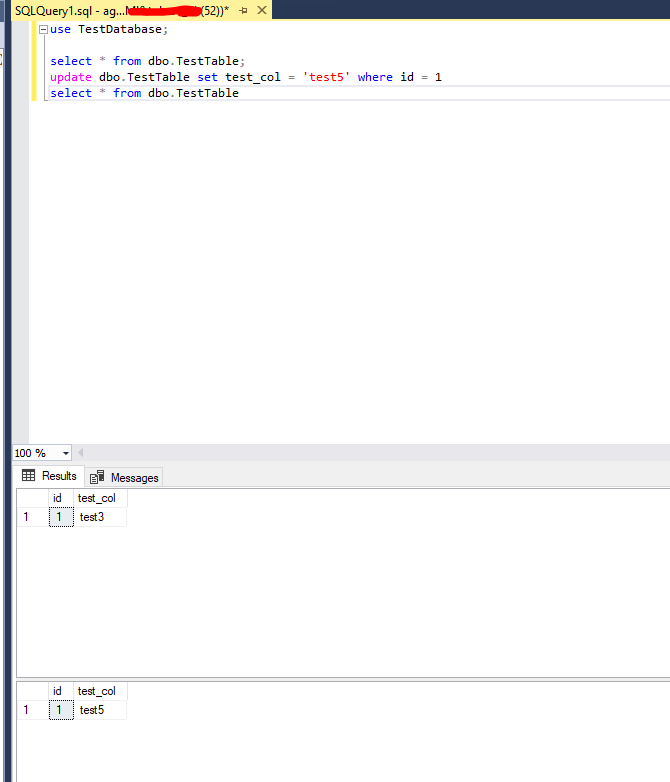
Сделаем простые insert, select и update запросы в нашу базу SQL Server.
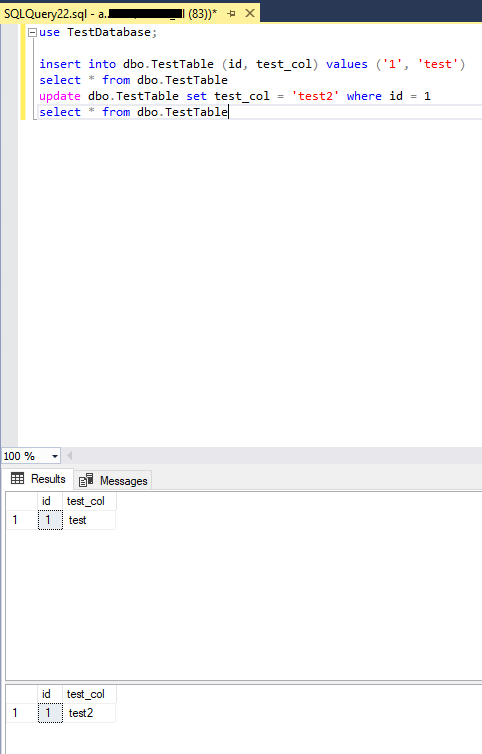
Теперь проверим автоматическую отработку отказа основной реплики. Просто завершите процесс sqlservr.exe на TESTNODE2.
Проверяем состояние группы доступности на оставшемся узле – TESTNODE1\NODE1.
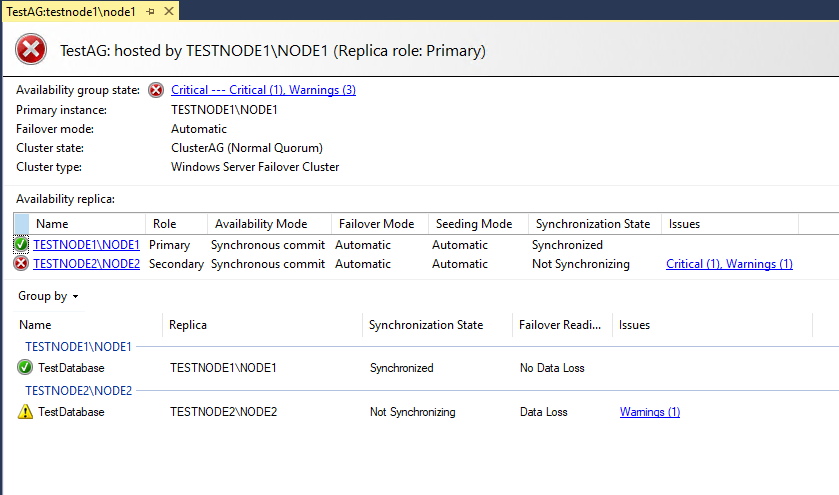
Кластер автоматически перевёл статус реплики testnode1\node1 в primary, так как testnode2\node2 стал недоступен.
Проверим состояние слушателя, потому что соединения клиентов будут поступать именно на него.
В моём случае я успешно соединился со слушателем, но при доступе к базе данных появилась ошибка
Unable to access database 'TestDatabase' because it lacks a quorum of nodes for high availability. Try the operation again later.

Эта ошибка возникла из-за параметра “Required synchronized secondaries to commit”. Так как при настройке мы выставляли это значение в 1, Always On не даёт подключиться к базе данных, потому что у нас осталась всего одна primary реплика.
Установим это значение в 0 и попробуем снова.
Включаем testnode2 и проверяем статус группы.
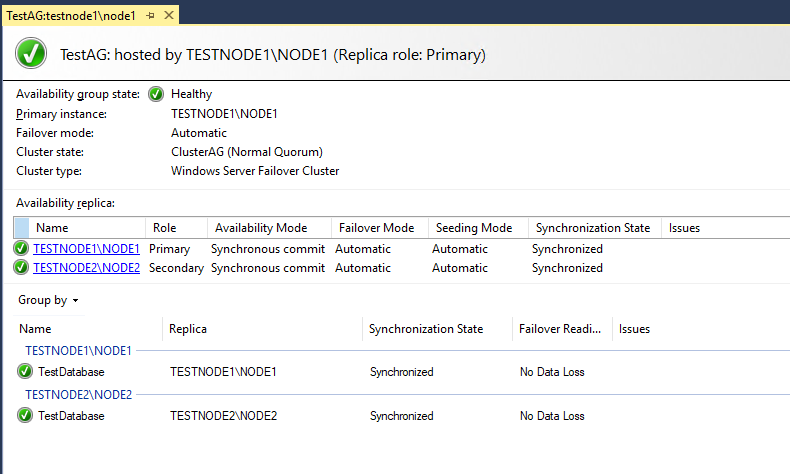
Статус Primary реплики остался у testnode1, а testnode2 стал вторичной репликой. Данные, которые мы меняли на testnode1 при выключенной testnode2 успешно синхронизировались после включения машины.
На этом тестирование закончено. Мы убедились всё работает корректно и при критическом сбое данные останутся доступны для read/write доступа.
Группы доступности Always On достаточно просты в настройке. Если перед вами стоит задача построить отказоустойчивое решение на базе SQL Server, то группы доступности отлично справятся с этой задачей.
С выпуском SQL Server 2017 и SQL Server 2019 в SQL Server Management Studio 18.x появились настройки Always On, которые раньше были доступны только через T-SQL, поэтому рекомендуется пользоваться последней версией SSMS.


Было бы очень хорошо, если бы описали, как правильно бекапить базы, которые находятся в режиме «Always On», средствами SQL Server Management Studio
Устанавливаешь подключение к AG и делаешь резервную копию… В чём проблема то ? ))
Вопрос. Обязательно ли запускать службы ms sql под одной доменной учетной записью, или можно под разными и базы в AlwaysOn продолжат функционировать?
Делал на linux. Не понимаю, почему не могу слушателя пинганут!((( Он не доступен из вне.
ip свободный. Маска верно указана.
Парни нет идей почему так может быть?
добрый день. делаю по Вашей статье, подскажите пожалуйста что за сервер листенер?
можно указать любой сервер?
А можно ли расположить обе ноды кластера в разных подсетях (например, разнесение по разным датацентрам для отказоустойчивости)? Или такое решение будет не слишком правильным с точки зрения скорости доступа (ведь между ДЦ канал может быть медленным)?
Отмечу, что при создании кластера в файерволе должен быть разрешён диапазон адресов APIPA: 169.254.0.0/16.
как по best practice разорвать группу доступности Always On в SQL Server, чтобы вывести из эксплуатации сервер реплики и оставить основной?
1. Обеспечение высокой доступности (High Availability)
Даже если ваши VM уже работают на хостах, объединенных в кластер, сами виртуальные машины могут не поддерживать автоматическое переключение в случае отказа. Создание кластера VM позволяет настроить высокую доступность на уровне приложений и сервисов внутри VM.
Пример: Кластеризация SQL Server Always On для обеспечения доступности базы данных. Если одна из VM, на которой запущен экземпляр SQL Server, выйдет из строя, другой экземпляр возьмет на себя обработку запросов.
2. Распределение нагрузки (Load Balancing)
Кластер VM позволяет организовать балансировку нагрузки между узлами, что улучшает производительность и снижает нагрузку на отдельные VM.
Пример: Веб-серверы, на которых крутится нагруженное веб-приложение, распределяют трафик между несколькими виртуальными машинами, что снижает нагрузку на каждую из них и повышает отклик приложения.
3. Масштабирование приложения (Scalability)
Кластер из виртуальных машин позволяет горизонтально масштабировать приложения, добавляя новые узлы при увеличении нагрузки.
Пример: В случае увеличения трафика на веб-приложение можно легко добавить еще несколько виртуальных машин, которые автоматически присоединятся к кластеру для распределения нагрузки.
4. Плановое обслуживание (Planned Maintenance)
Кластеризация VM позволяет переносить нагрузку с одной VM на другую во время обновлений или технического обслуживания.
Пример: Если требуется провести обновление программного обеспечения или обновить конфигурацию на одном из хостов, кластер VM позволяет перенести рабочие нагрузки на другие узлы кластера, минимизируя время простоя.
5. Использование функционала Quorum для отказоустойчивости
Кластеры VM поддерживают конфигурации кворума, что позволяет более гибко управлять отказоустойчивостью, особенно в случае с асинхронными приложениями, где возможны короткие периоды разрыва связи между нодами.
Пример: Приложения, которые критически зависят от постоянного взаимодействия, такие как базы данных, могут продолжать работать даже при временной недоступности одного из узлов, если настроен правильный кворум кластера.
6. Восстановление при сбое (Disaster Recovery)
Кластеризация VM позволяет упростить восстановление при сбое, так как кластер может быть настроен для автоматического запуска резервных копий VM в случае сбоя.
Пример: В случае полного выхода из строя одного из хостов, другой хост в кластере может автоматически активировать резервные VM для минимизации простоя.
Эти ситуации показывают, что создание кластера виртуальных машин может быть полезным и в среде, где хосты уже объединены в кластер на уровне Hyper-V.
Вы сказали:
как по best practice разорвать группу доступности Always On в SQL Server, чтобы вывести из эксплуатации сервер реплики и оставить основной?
ChatGPT сказал:
ChatGPT
Разрывание группы доступности Always On в SQL Server — это многошаговый процесс, который требует осторожного подхода, чтобы минимизировать риск потери данных и обеспечить доступность основной базы данных. Следующие шаги соответствуют best practices:
1. Проверьте текущий статус группы доступности
Убедитесь, что реплика, которую вы планируете отключить, работает в режиме синхронизации (Synchronous Commit) и является вторичной. Это гарантирует, что все изменения синхронизированы.
Если реплика работает в асинхронном режиме (Asynchronous Commit), обязательно проверьте, что данные актуальны и синхронизированы перед отключением.
2. Переведите рабочую нагрузку на основную реплику
Если вторичная реплика используется для чтения или других операций, перенаправьте эти задачи на основную реплику.
Оповестите команды, работающие с базой данных, об изменениях, чтобы исключить неожиданные сбои.
3. Удалите вторичную реплику из группы доступности
Откройте SQL Server Management Studio (SSMS) и выберите группу доступности, к которой принадлежит реплика.
В разделе Availability Replicas (Реплики доступности) удалите вторичную реплику из группы, выбрав команду Remove Replica (Удалить реплику).
Это безопасно отключит вторичную реплику и предотвратит её участие в синхронизации.
4. Отключите режим группы доступности
После удаления всех вторичных реплик, выключите Always On для самой группы доступности.
Для этого в SSMS найдите нужную группу доступности, щелкните правой кнопкой мыши и выберите Remove Availability Group (Удалить группу доступности).
SQL Server откажется от использования группы доступности, оставив базу данных в обычном режиме.
5. Удалите оставшиеся настройки на выводимом сервере
После удаления группы доступности отключите функцию Always On на SQL Server, который вы выводите из эксплуатации, чтобы освободить ресурсы.
Зайдите в SQL Server Configuration Manager, выберите SQL Server Service, снимите галочку с Enable Always On Availability Groups, затем перезагрузите SQL Server Service для применения изменений.
6. Проверьте статус основной базы данных
Убедитесь, что основная база данных находится в статусе ONLINE и работает в стандартном режиме.
Проверьте доступность приложений и служб, которые используют основную базу данных, чтобы исключить нарушения работы.
7. Создайте резервную копию основной базы данных
Как завершающий шаг, выполните полное резервное копирование основной базы данных. Это обезопасит данные на случай непредвиденных сбоев после изменения конфигурации.
Следуя этим шагам, вы сможете безопасно вывести сервер реплики из эксплуатации, оставив основной сервер в работе.
1. Проверьте текущий статус группы доступности
Убедитесь, что реплика, которую вы планируете отключить, работает в режиме синхронизации (Synchronous Commit) и является вторичной. Это гарантирует, что все изменения синхронизированы.
Если реплика работает в асинхронном режиме (Asynchronous Commit), обязательно проверьте, что данные актуальны и синхронизированы перед отключением.
2. Переведите рабочую нагрузку на основную реплику
Если вторичная реплика используется для чтения или других операций, перенаправьте эти задачи на основную реплику.
Оповестите команды, работающие с базой данных, об изменениях, чтобы исключить неожиданные сбои.
3. Удалите вторичную реплику из группы доступности
Откройте SQL Server Management Studio (SSMS) и выберите группу доступности, к которой принадлежит реплика.
В разделе Availability Replicas (Реплики доступности) удалите вторичную реплику из группы, выбрав команду Remove Replica (Удалить реплику).
Это безопасно отключит вторичную реплику и предотвратит её участие в синхронизации.
4. Отключите режим группы доступности
После удаления всех вторичных реплик, выключите Always On для самой группы доступности.
Для этого в SSMS найдите нужную группу доступности, щелкните правой кнопкой мыши и выберите Remove Availability Group (Удалить группу доступности).
SQL Server откажется от использования группы доступности, оставив базу данных в обычном режиме.
5. Удалите оставшиеся настройки на выводимом сервере
После удаления группы доступности отключите функцию Always On на SQL Server, который вы выводите из эксплуатации, чтобы освободить ресурсы.
Зайдите в SQL Server Configuration Manager, выберите SQL Server Service, снимите галочку с Enable Always On Availability Groups, затем перезагрузите SQL Server Service для применения изменений.
6. Проверьте статус основной базы данных
Убедитесь, что основная база данных находится в статусе ONLINE и работает в стандартном режиме.
Проверьте доступность приложений и служб, которые используют основную базу данных, чтобы исключить нарушения работы.
7. Создайте резервную копию основной базы данных
Как завершающий шаг, выполните полное резервное копирование основной базы данных. Это обезопасит данные на случай непредвиденных сбоев после изменения конфигурации.
Следуя этим шагам, вы сможете безопасно вывести сервер реплики из эксплуатации, оставив основной сервер в работе.
Стоит добавить, что, если служба mssql работает не из под единой, доменной учётной записи, то придется настраивать кучу доступов. Так что сделать запуск службы из под единой учётки, гораздо проще и быстрее.
Не могу победить шаг — Listener.
есть srv1, соответственно node1 ip 1.1.1.1
есть srv2, соответственно node2 ip 1.1.1.2
есть srv3 — он является слушателем ip 1.1.1.3
Что нужно задать в задать в Create an availability listener?
Listener DNS Name
Port
Ip address
У вас 3 сервера в группе доступности, правильно. У каждого свой IP и hostname.
listener — это новое уникалное (виртуальное) имя кластера, по которому к нему будут обращаться клиенты (независимо от того, где сейчас сейчас основная реплика)